 Redis 8 来了——并且是开源的
Redis 8 来了——并且是开源的
了解更多


新推出的 RediSearch 1.6 增加了一些重要的新功能,包括别名、低级 API 和改进的查询验证,并将 Fork 垃圾回收设置为模块的默认设置。更重要的是,RediSearch 1.6 中的原始代码经过重构,显著提升了性能。性能提升带来了更好的用户体验,应用程序在搜索方面比以往任何时候都更具响应性。
(有关 RediSearch 1.6 新功能的更多信息,请参阅我们关于《宣布 RediSearch 1.6 版本发布》的博文。)
RediSearch 1.6 的性能提升究竟有多大?这就是本文的全部内容,我们稍后将展示结果。但为了充分理解性能问题,我们需要一种方法来正确比较数据库的搜索速度。
为了比较 RediSearch 1.6 版本与之前的 1.4 版本,我们创建了一个全文搜索基准测试工具。FTSB(根据MIT许可)专门设计用于帮助开发者、系统架构师和运维工程师找到最适合其工作负载的搜索引擎。它允许我们生成数据集,然后对常见搜索查询的读写性能进行基准测试。它支持两个不同特性的数据集:
为了获得可重现的结果,要插入的数据和要运行的查询都是预先生成的,并尽可能使用原生的 Go 客户端连接到各个数据库。为了设计一个通用的基准测试套件,所有延迟结果都包含网络往返时间 (RTT),以衡量客户端往返的时间,以便我们能够正确比较其他数据库。
我们鼓励您亲自运行这些基准测试,以独立验证在您的硬件和选定数据集上的结果。更重要的是,我们正在寻求对该工具的反馈和扩展请求,包括更多用例(例如电子商务、JSON 数据、地理数据等)和问题领域。如果您是某个全文搜索引擎的开发者,并希望将您的数据库包含在FTSB中,请随时提出 issue 或提交 pull request 来添加它。
我们在 Amazon Web Services 实例上运行了性能基准测试,这些实例是通过我们的基准测试基础设施提供的。基准测试客户端和数据库服务器都运行在单独的 c5.24xlarge 实例上。测试在一个单节点 Redis Enterprise 集群设置上执行,版本为 5.4.10-22,数据分布在 10 个主分片上。
除了这个主要的基准测试/性能分析场景,我们还进行了网络、内存、CPU 和 I/O 的基线基准测试,以便了解底层网络和虚拟机特性。我们将基准测试基础设施表示为代码,以便于复制和稳定。
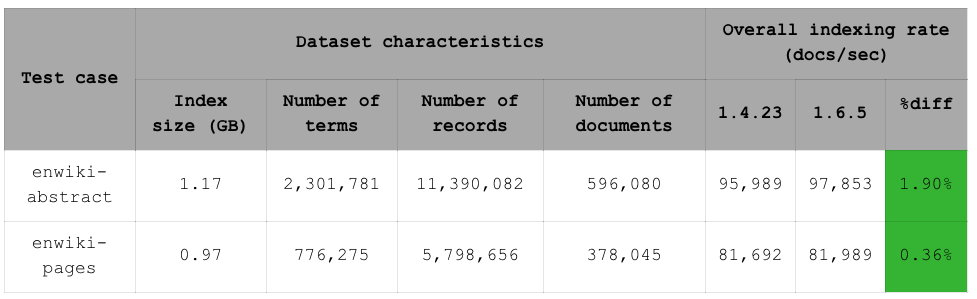
下表显示了本次基准测试中使用的数据集大小。它还显示了每个数据集的总索引速率。您可以看到 RediSearch 1.6 在数据摄取方面没有降低性能
FSTB 目前支持三种全文搜索查询,如下表所示(请记住延迟结果包含 RTT)。请注意,我们计划通过更多样化的读取查询集来扩展此基准测试套件。
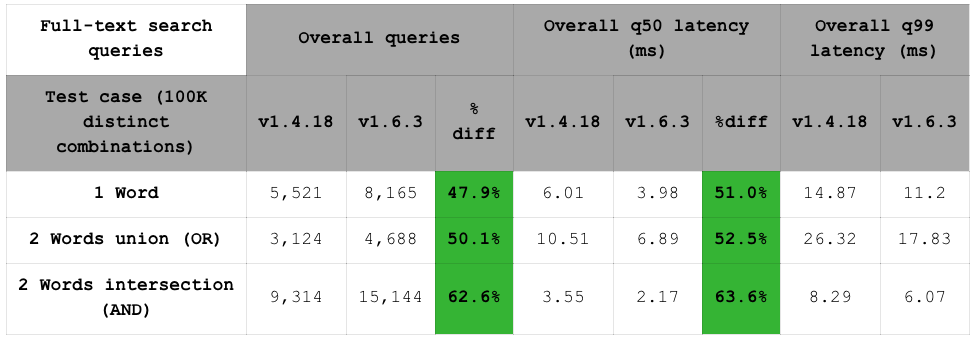
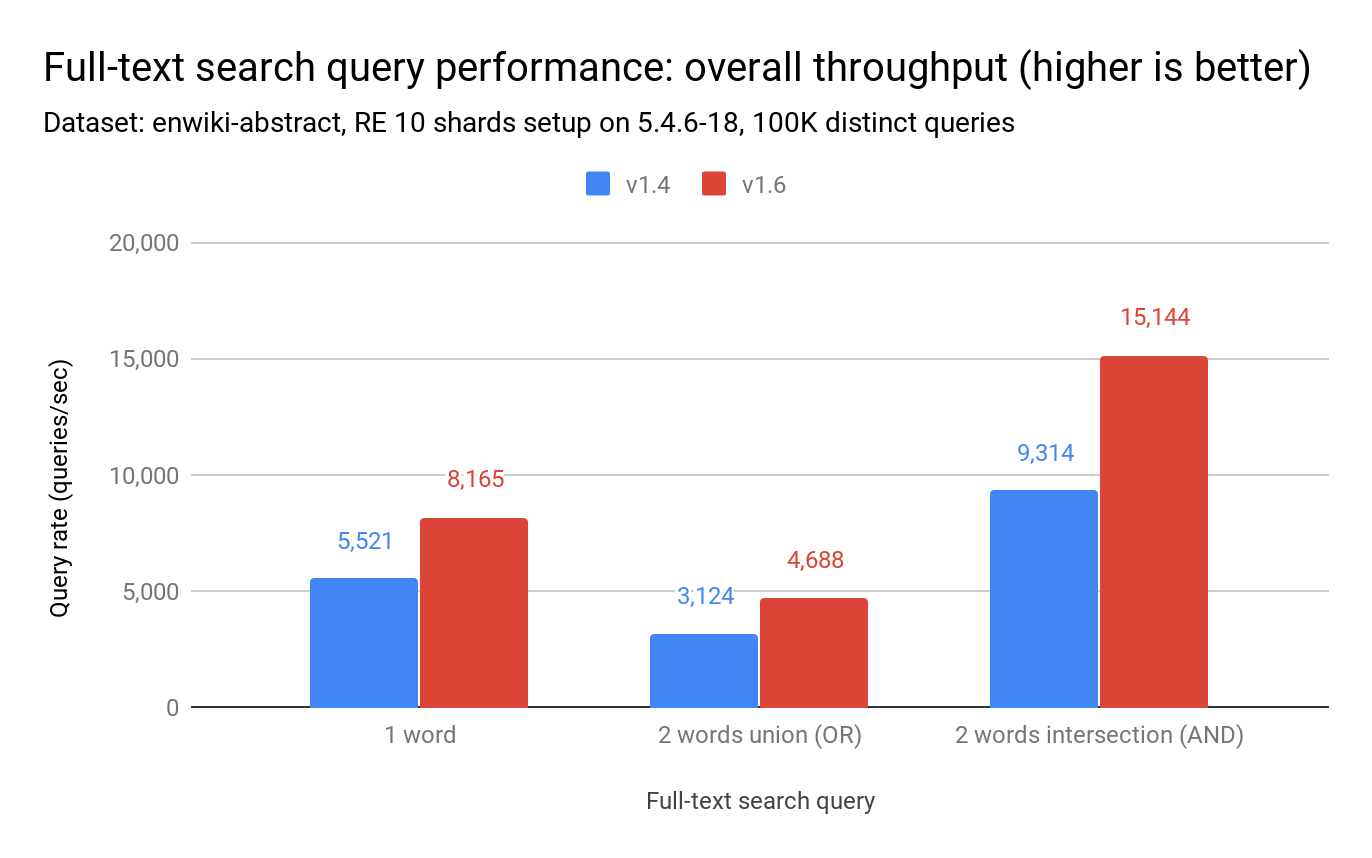
我们可以从上表中观察到,RediSearch 1.6 改进的 q99 使其更具可预测性,延迟峰值更少。下图显示,与 RediSearch 1.4 相比,RediSearch 1.6 将吞吐量提高了 48% 至 63%。
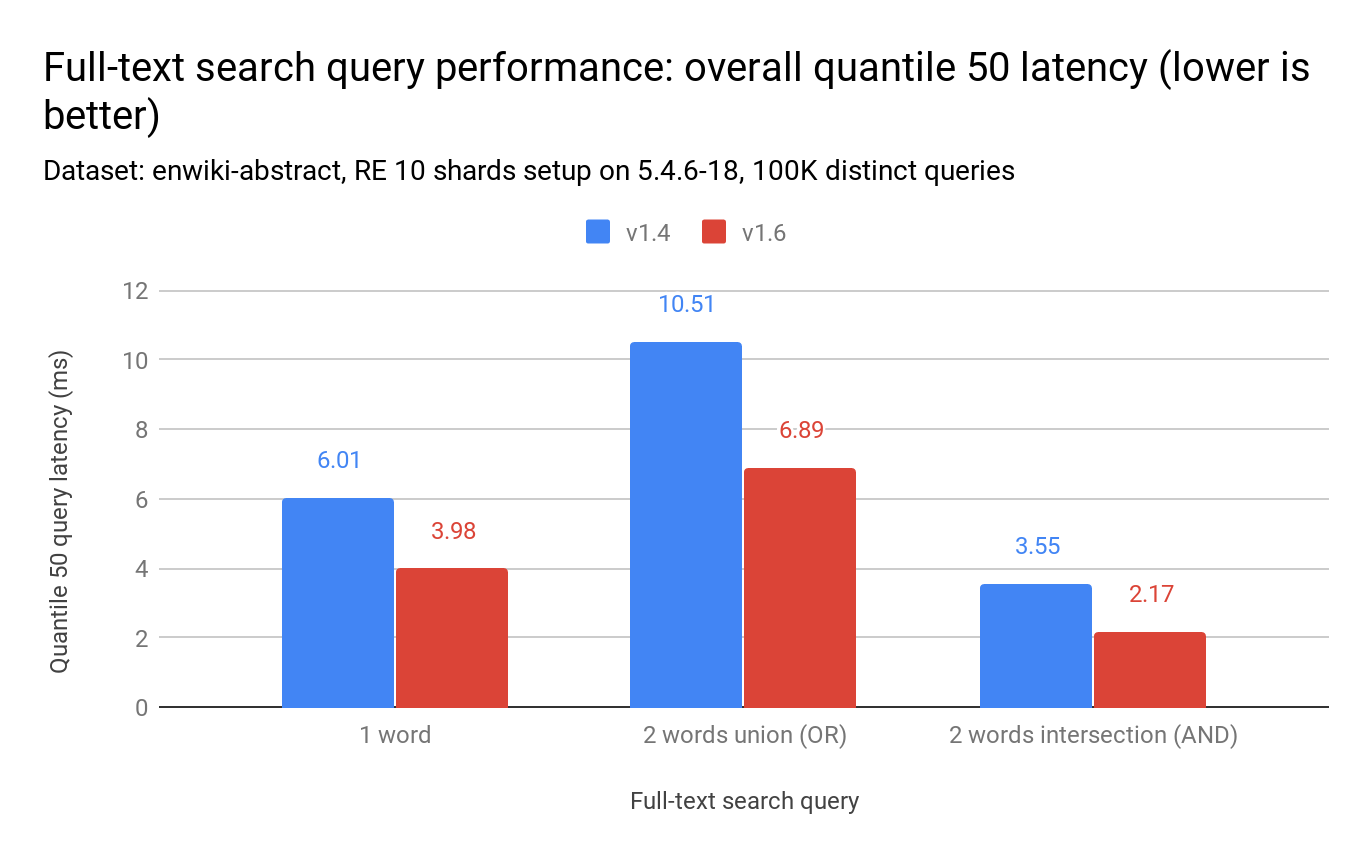
同样,延迟(q50)降低了 51% 至 64%。
除了简单的搜索查询,我们还添加了一组聚合查询。每个查询具体做什么的完整详情可以在我们的基准测试仓库中找到(同样,请记住延迟结果包含 RTT):
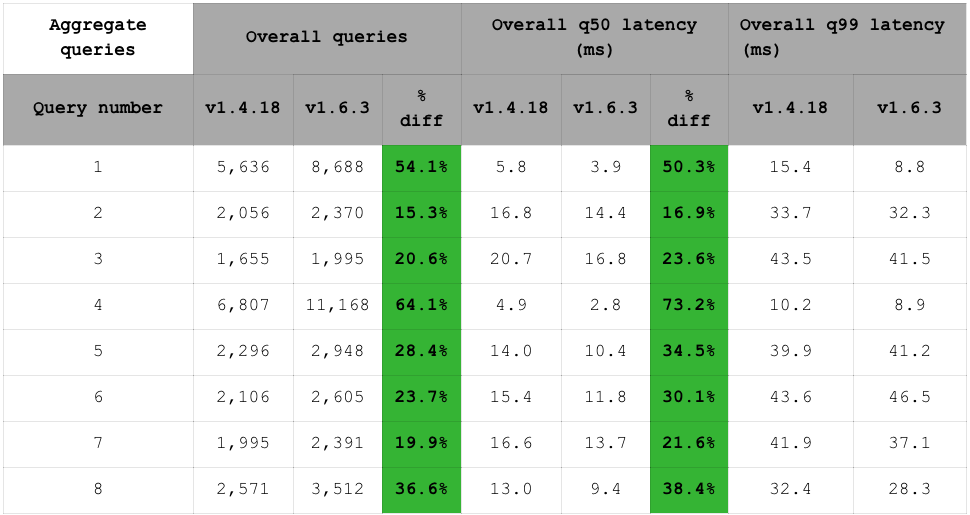
在此方面,与 RediSearch 1.4 相比,RediSearch 1.6 也提高了性能。吞吐量增加了 15% 至 64%:
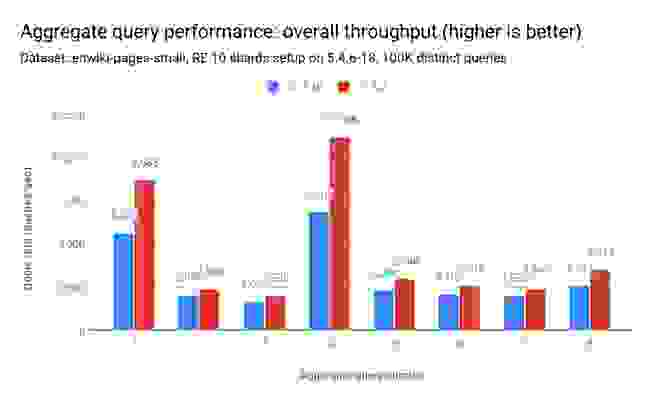
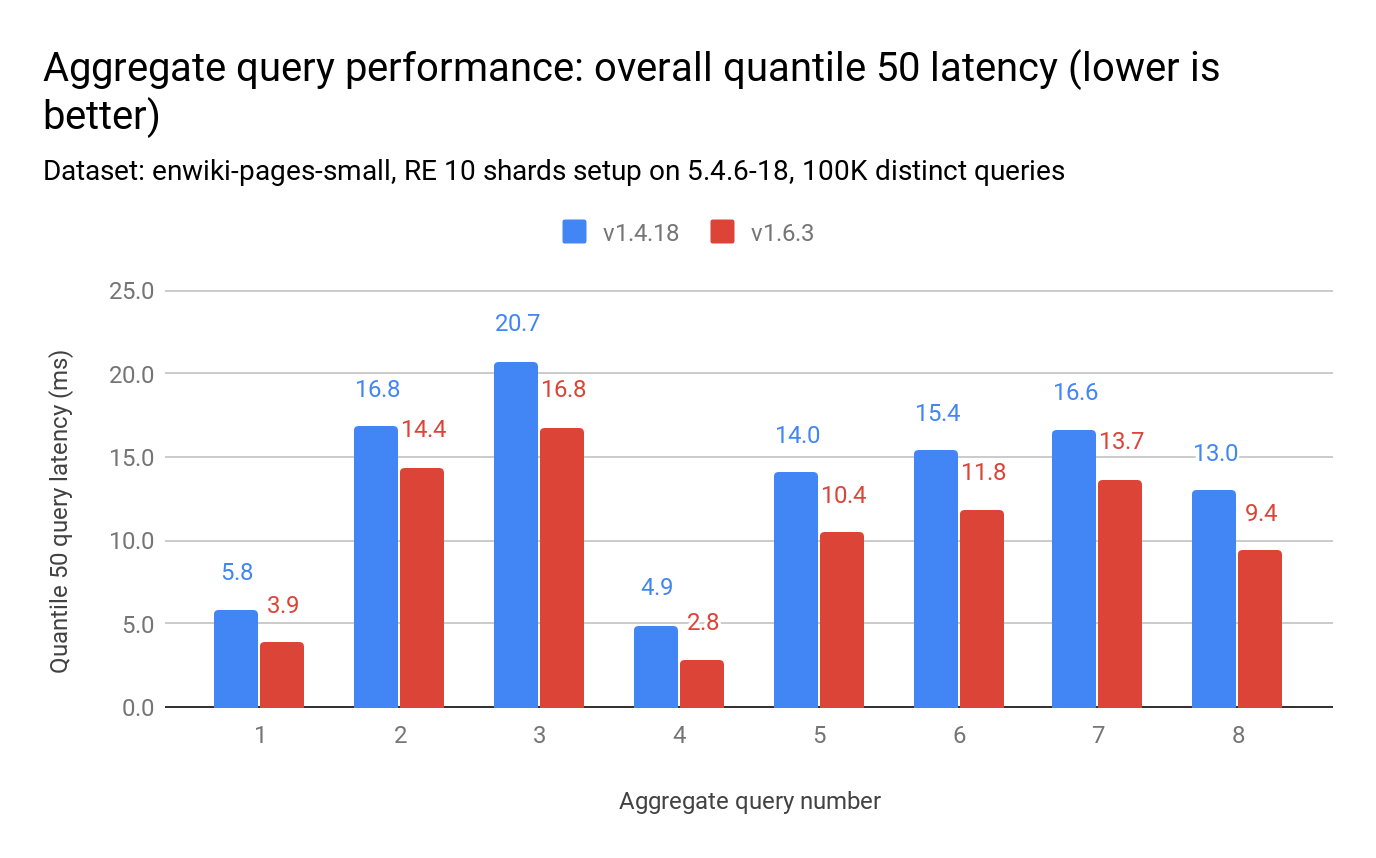
同样,延迟(q50)降低了 17% 至 73%:
总而言之,您可以看到 RediSearch 1.6 相较于 1.4 版本带来了显著的性能优势。具体来说,RediSearch 1.6 将简单的全文搜索吞吐量提高了高达 63%,同时将延迟(q50)降低了高达 64%。对于聚合查询,吞吐量增加了 15% 至 64%。
同样重要的是,引入全文搜索基准测试帮助我们持续监控不同版本 RediSearch 之间的性能,事实证明这对于消除性能瓶颈和强化我们的解决方案具有极其重要的价值。

