 Redis 8 已发布,并且是开源的
Redis 8 已发布,并且是开源的
了解更多

流行的 RediSearch 模块旨在通过添加具有超快速全文搜索功能的二级索引来扩展 Redis 的功能。RediSearch 广受好评,已获得超过 150,000 次 Docker 拉取、2,000 个 GitHub star、230 个 fork 以及约 10 种不同语言的 10 个驱动程序。客户已经从中受益——请观看 此视频,了解 GAP 如何使用 Redis 扩展了 100 倍。
今天,我们很荣幸地宣布推出 RediSearch 1.6 版,它重构了原始模块以提升性能,并增加了一些重要的新功能——包括别名(aliasing)、低级 API 和改进的查询验证——同时也将 Fork 垃圾回收设为模块的默认行为。所有这些设计都旨在让 RediSearch 的开发更加强大和便捷。
我们最初创建 RediSearch 是为了支持一个(或数量有限的)二级索引,该索引可以通过扩展 Redis 来扩展。多年来,Redis 用户转向 RediSearch 来满足各种用例的需求,这些用例经常在查询同一索引的同时删除并重新创建它,或者创建数千个小型、短期存在的索引。在 RediSearch 1.6 中,我们重构了代码库,以更好地支持这些用例。通过这样做,我们改进了查询验证,并将性能提升高达 73%!我们还增加了两个重要的新功能:别名(Aliasing)允许 Redis 引用现有索引并轻松切换到另一个索引,而新的低级 API 使 RediSearch 作为一个库提供,可供用 C 或 Rust 编写的其他 Redis 模块使用。这意味着开发人员无需学习额外的搜索查询语言即可使用任何 Redis 模块。通过这个库,模块可以轻松添加二级索引功能。RedisGraph 2.0 是第一个利用此功能并提供全文搜索能力的通用 Redis 模块。RediSearch v.1.6 版中添加功能的完整列表可以在 GitHub 上找到。
根据我们使用全文搜索基准测试(FTSB)进行的测试,与 1.4 版本相比,RediSearch 1.6 带来了显著的性能优势。具体来说,RediSearch 1.6 将简单全文搜索吞吐量提高了高达 63%,同时将延迟(q50)降低了高达 64%。对于聚合查询,吞吐量提高了 15% 到 64%。
(有关 RediSearch 1.6 性能改进的更多信息,请参阅我们关于 RediSearch 1.6 性能提升高达 64% 的博客文章。)
RediSearch 最强大的功能之一是文档的每次更新都会原子地更新索引。与其他基于 Lucene 的搜索引擎不同,RediSearch 索引不必追赶数据。换句话说,您总是能读到自己写入的数据。
然而,在某些应用中,重新加载整个索引比跟踪两次批量加载之间的差异更高效或更方便。在运行时更新应用程序以连接到新加载的索引且不中断服务几乎是不可能的,因此我们引入了别名以使 RediSearch 更加灵活和强大。值得注意的是,ElasticSearch 用户会发现 RediSearch 中添加别名将简化他们迁移到 Redis 的路径,如下例所示。
别名允许您将应用程序查询从逻辑索引名称重定向到物理底层索引。更新别名允许您透明地将应用程序查询重定向到另一个物理索引,而无需停机!
这个简单的例子解释了别名如何与 RediSearch 命令一起使用
redis:6379> FT.CREATE idxA SCHEMA title TEXT
OK
redis:6379> FT.ADD idxA a:doc1 1.0 FIELDS title "plump fiction"
OK
redis:6379>
OK
redis:6379> FT.SEARCH movies "@title:fiction"
1) (integer) 1
2) "a:doc1"
3) 1) "title"
2) " fiction"
redis:6379> FT.CREATE idxB SCHEMA title TEXT
OK
redis:6379> FT.ADD idxB b:doc1 1.0 FIELDS title "pulp fiction"
OK
redis:6379>
OK
redis:6379> FT.SEARCH movies "@title:fiction"
1) (integer) 1
2) "b:doc1"
3) 1) "title"
2) " fiction"
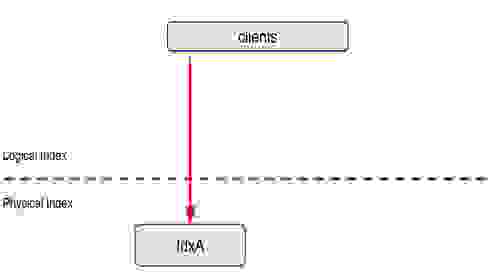
未来,有机会增强此功能,使其能够为一个别名指定多个索引,例如,解决查询负责不同文档集的两个索引的问题。
自从创建 Redis 模块 API 以来,Redis 和 Redis 社区已经创建了大量的模块。有些为 Redis 添加了全新的数据库模型,有些允许您使用数据执行代码,还有些为 Redis 添加了新的数据结构。然而,我们注意到有几个模块开始构建自己专有的数据索引方式。例如,在 RedisGraph 中,图节点属性的索引保存在 ziplist 中,而 RedisTimeSeries 则使用有序集合来查询具有特定标签条件的时间序列数据。
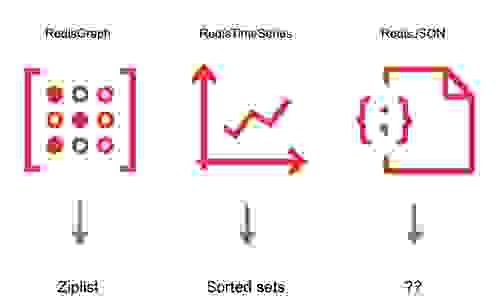
这些实现提供了基本的搜索功能,但对于 RediSearch 1.6,我们希望消除代码重复,并通过通用的查询语言增强关键用例中的搜索功能。例如,在图数据库中,对节点属性进行模糊搜索以启用图辅助搜索是很常见的。同时,时间序列用例通常涉及所有标签匹配特定前缀的时间序列。其他 Redis 模块可以从二级索引支持中受益。想象一下,如果 RedisJSON 拥有全文搜索功能,您能做什么!
因此,在 RedisSearch 1.6 中,我们创建了一个低级 API,其他 Redis 模块可以使用它。RedisGraph v2.0 是第一个使用此模块的通用 Redis 模块。图辅助搜索允许您在图中找到属性与全文搜索查询匹配的节点,并根据这些节点在图中的连接对其进行排名。
LinkedIn 的搜索功能是图辅助搜索的一个很好的例子:网络中与您关系更近的人和公司在搜索结果中排名更高。我们正在继续进行 RedisTimeSeries 的低级 API 开发,并且您已经可以试用嵌入了 RediSearch 的 RedisJSON 2.0 预览版。
与大多数基于倒排索引的搜索引擎一样,当您删除或更新文档时,RediSearch 会有效地将文档标记为待删除。垃圾回收过程会定期运行以回收存储已删除文档所占用的内存。将文档标记为已删除并使物理删除异步进行,可以减少命令执行时间,同时保持查询的正确性。
在 RediSearch 1.4 中,默认行为是锁定主线程,这会在垃圾回收期间引入读取延迟的峰值。为了克服这个问题,RediSearch 1.4 提供了一个可选的 Fork GC,它与主查询进程并行运行,允许不中断地扫描任何已删除的文档。这种方法为高流量环境提供了卓越的性能,在高流量环境中会发出许多查询和/或执行许多写入操作,因此我们在 RediSearch 1.6 中将此行为设为默认设置。
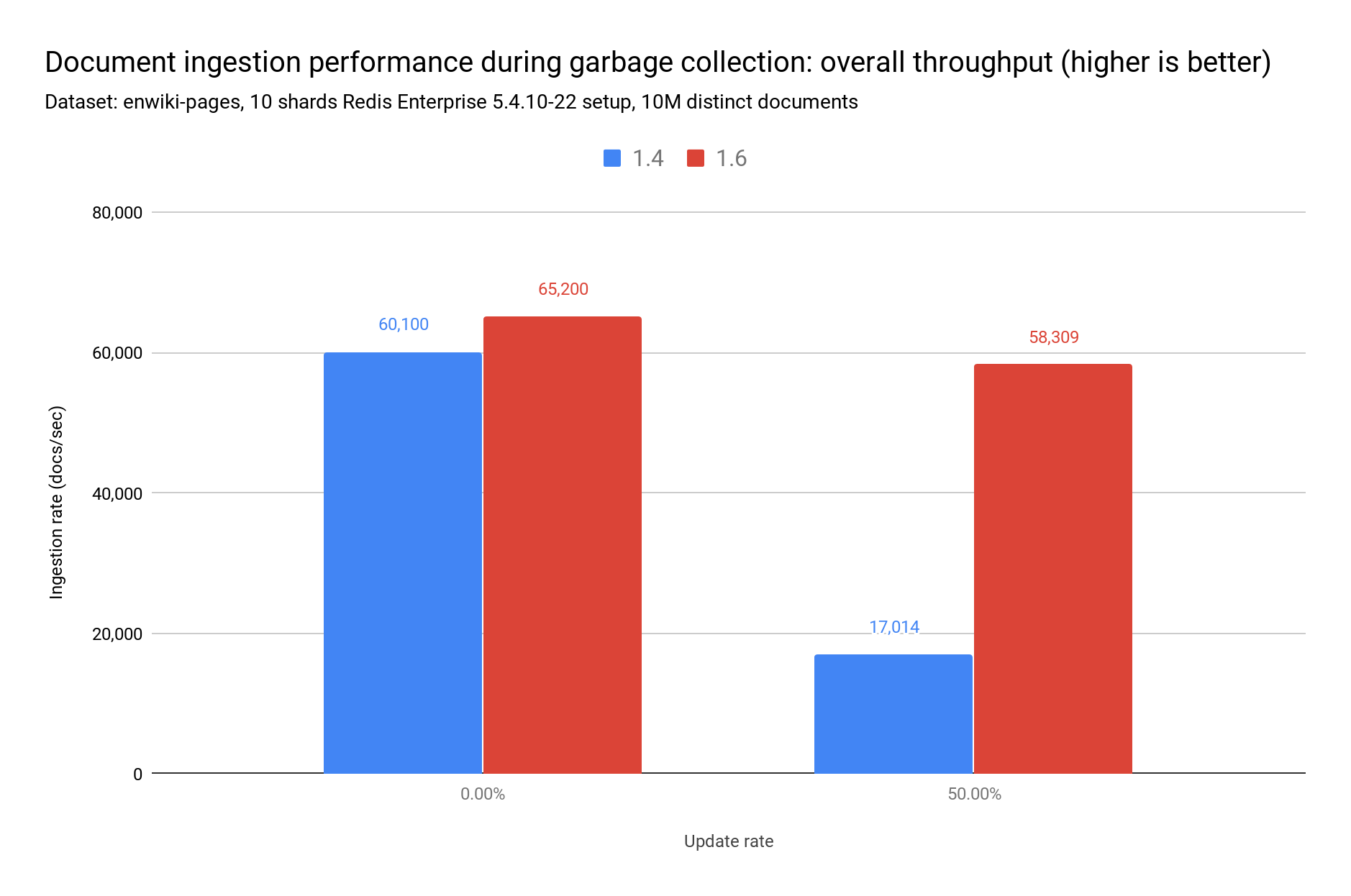
您可以在这个两阶段测试中看到 Fork GC 的优势。在第一阶段,我们插入 1000 万个新文档。在此阶段之后,我们删除索引。在第二阶段,流量是混合的:插入和更新 500 万个文档。然而,对于每个写操作,还有一个更新操作(更新率为 50%),因此总共也是 1000 万个操作。

图表清楚地显示了当更新率为 50% 时,传统垃圾回收性能如何迅速下降。总的来说,我们观察到在使用新的 Fork 垃圾回收时,低更新率下的性能提高了 8%,高更新率下性能提升高达 70%:
最后,RediSearch 1.6 还改进了查询验证。如果查询被确定包含逻辑或语法错误,则会向用户返回相应的错误消息,而不是让查询执行但没有结果。当提交无法识别的关键字时,RediSearch 1.6 也会返回错误。这种查询验证将增强开发人员体验并降低 RediSearch 的学习曲线。另外请注意,RediSearch 1.6 支持 RedisInsight,这是我们最近发布的用于管理 Redis 部署的基于浏览器的界面。
展望未来,我们的路线图上有许多有趣的功能,例如支持多边形搜索以及在单个分片上为读取查询创建更高的并行度。这将有助于我们在不增加分片数量的情况下实现更高的聚合查询吞吐量。
当然,比新功能更重要的是,1.6 版是迄今为止最快的 RediSearch(在此了解更多关于 RediSearch 1.6 性能改进的信息)。您的应用程序将在所有类型的查询中体验到更一致的延迟,峰值更少。
最后,我们要感谢通过在早期发布候选版本中发现错误,帮助使 RediSearch 1.6 更强大的 Redis 社区成员。

