 Redis 8 来了——它是开源的
Redis 8 来了——它是开源的
了解更多


我们很高兴地宣布 RedisGears 正式可用 (GA),它是一个在 Redis 中提供无限可编程性的无服务器引擎。开发人员可以使用 RedisGears 来提高应用程序性能并实时处理数据,而架构师可以利用它来简化架构。
作为在 Redis 中执行实现数据流的 函数 的动态框架,RedisGears 抽象了数据的分布和部署,以使用 Redis 中的多种模型加速数据处理。RedisGears 允许您在 Redis 中编程您想要的一切,将函数部署到各种环境,简化您的架构并降低部署成本,并在数据驻留的地方运行您的无服务器引擎。
RedisGears 可用于多种用例
除了宣布 RedisGears 正式可用之外,我们还推出了它的第一个“配方”(recipe)。“配方”是一组函数及其任何依赖项的集合,它们共同解决了一个更高级别的问题或用例。我们的第一个配方是 rgsync。这也被称为 write-behind(写时回源), 此功能允许您将 Redis 作为您的前端数据库,同时 RedisGears 保证所有更改都被写入您现有的数据库或数据仓库系统。
为了帮助您理解 RedisGears 的强大功能,我们将首先解释 RedisGears 的架构及其优势。然后我们将讨论这些优势如何应用于 write-behind,并通过我们创建的演示应用程序展示其行为。
RedisGears 的核心是一个引擎,它通过可编程接口执行用户提供的流程或函数。函数可以由引擎以 ad-hoc map-reduce 方式执行,或由不同的事件触发进行事件驱动处理。存储在 Redis 中的数据可以被函数读取和写入,并且内置协调器促进在集群中处理分布式数据。
概括来说,此图描绘了 RedisGears 的组件
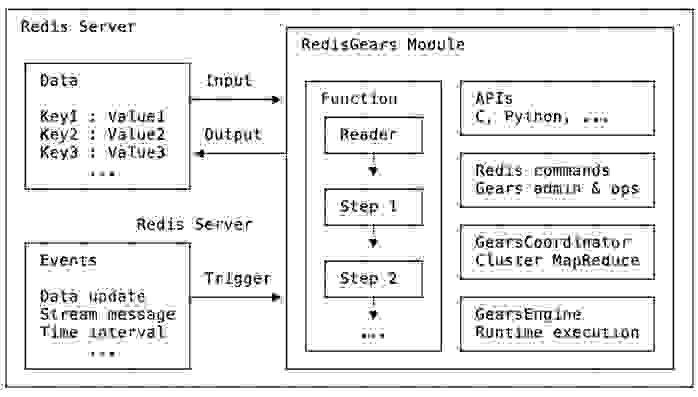
RedisGears 有三个主要组件
在这三个核心组件之上,RedisGears 包括一个用于可编程性的快速低级 C-API。您今天可以通过 Python 集成此 C-API,未来还将支持更多语言。
RedisGears 通过尽可能靠近您的数据运行函数来最大限度地减少执行时间和分片之间的数据流。通过将无服务器引擎置于内存中(即您的 Redis 数据所在的位置),它消除了获取数据所需耗时的往返过程,从而加快了事件和流的处理速度。
RedisGears 让您“一次编写,随处部署”。您可以为独立的 Redis 数据库编写函数,并将其部署到生产环境,而无需为集群数据库调整脚本。
将实时数据与无服务器引擎相结合,使您无需多个客户端和数据库连接器的开销即可跨数据结构和数据模型处理数据。这简化了您的架构并降低了部署成本。
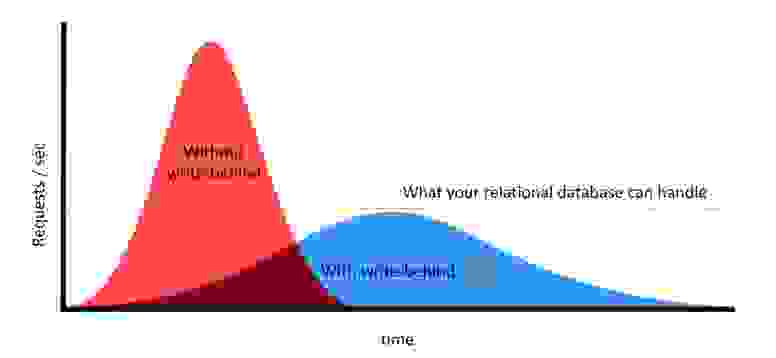
应对用户/请求数量突然激增的能力是现代公司和组织必须考虑的问题。例如,黑色星期五和网络星期一的流量可能远远超过普通日子的流量。
未能规划应对此类高峰可能导致性能低下、意外停机,并最终造成收入损失。另一方面,针对这些高峰过度扩展解决方案也可能成本高昂。关键在于找到一个既能满足需求又具有成本效益的解决方案。
传统的基于关系/磁盘的数据库通常无法应对负载的显著增加。这就是 RedisGears 发挥作用的地方。RedisGears 的 write-behind 功能依赖于 Redis 来完成繁重的工作,异步管理更新,减轻后端数据库的负载和减少峰值。RedisGears 还保证所有更改都被写入您现有的数据库或数据仓库系统,保护您的应用程序免受数据库故障的影响,并将应用程序的性能提升到 Redis 的速度。这极大地简化了您的应用程序逻辑,因为它现在只需要与单个前端数据库 Redis 通信。write-behind 功能最初支持 Oracle、MySQL、SQL、SQLite、Snowflake 和 Cassandra。
下图显示了 RedisGears 的 write-behind 功能的架构:
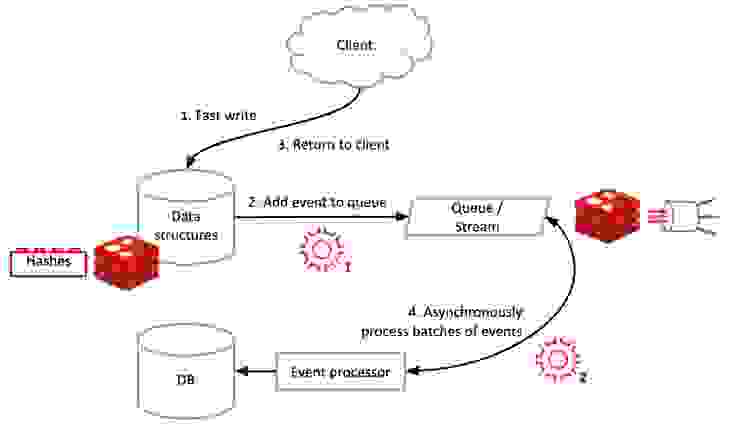
其工作原理如下
这两个函数共同组成了我们所说的 RedisGears 的“配方”。(请注意,write-behind 的配方捆绑在 rgsync(RedisGears 同步)包中,以及其他几个数据库同步配方。)
如上所述,第三步仅在事件成功添加到流中时发生。这意味着如果在客户端收到写操作的确认后出现问题,Redis 的复制、自动故障转移和数据持久化机制保证更新事件不会丢失。默认情况下,write-behind RedisGears 功能为写操作提供了 至少一次交付(at least once delivery) 的特性,这意味着数据将至少写入目标一次,但在发生故障时可能会写入多次。如果需要,可以将 RedisGears 函数设置为提供 精确一次(exactly once) 交付语义,确保任何给定的写操作在数据到达目标数据库后仅执行一次。
使用 write-behind 提升应用程序性能
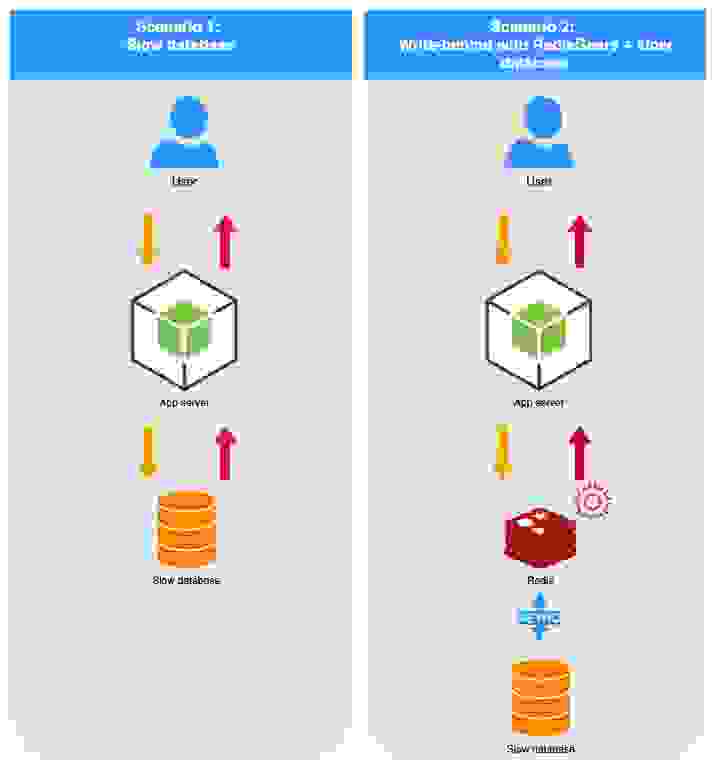
为了展示 write-behind 的优势,我们开发了一个 演示应用程序,其中我们添加了端点以支持两种场景:
在此示例中,我们使用 MySQL 作为后端数据库,以便于测试和重现。
为了模拟应用程序中的高峰,我们使用 k6 创建了一个尖峰测试,模拟了从 1 到 48 个并发用户的短暂爆发。
为了检查整体系统如何应对尖峰,我们跟踪了应用程序上实现的 HTTP 负载和延迟以及底层数据库系统的性能。下图展示了这两种场景——左侧区间显示了仅使用 MySQL 的解决方案结果,右侧区间显示了使用 RedisGears 的 write-behind 场景的结果。
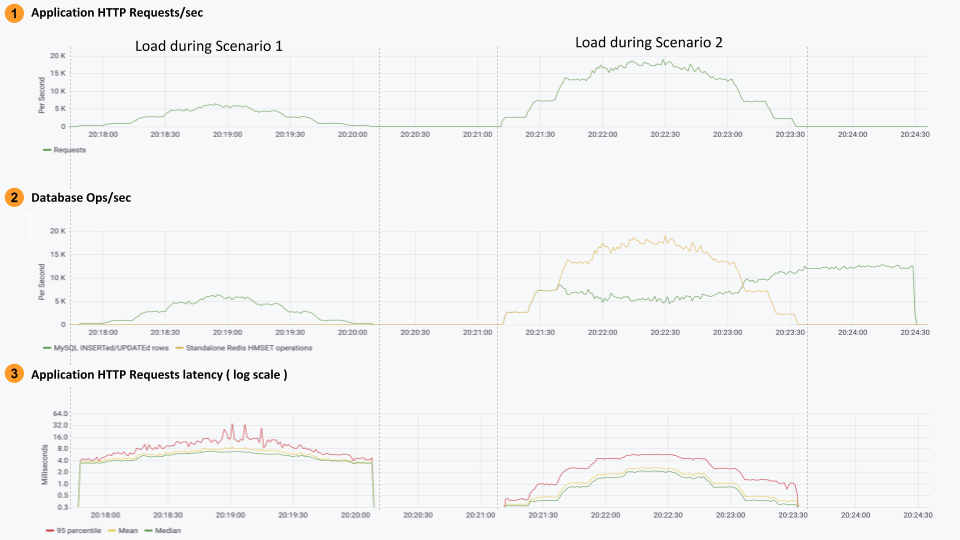
此图表显示了一些重要的发现
我们对 RedisGears 和 write-behind 感到非常兴奋。我们相信 write-behind 用例仅仅是 RedisGears 可以解决的无限问题的开始。
我们希望这篇博客文章能鼓励您尝试 RedisGears。请访问 RedisGears.io,其中包含大量入门示例和提示。您可以在这里找到更多有趣的演示:
新版本的 RedisInsight 即将发布,将包含对 RedisGears 的支持,用于执行函数和查看 RedisGears 中注册的函数。最后为您呈现一个快速 GIF,展示您可以期待的内容
编程愉快!

