 Redis 8 已推出——并且它是开源的
Redis 8 已推出——并且它是开源的
了解更多


为了对我们新发布的 RedisTimeSeries 1.2 模块的性能进行基准测试,我们使用了时序数据库基准测试套件 (TSBS)。TSBS 是一系列基于 InfluxDB 和 TimescaleDB 公开工作的 Go 程序,旨在让开发者生成数据集,然后对读写性能进行基准测试。TSBS 支持许多其他时序数据库,这使得比较不同数据库变得简单直接。
要了解更多关于 RedisTimeSeries 1.2 的信息,请参阅 RedisTimeSeries 1.2 版本发布!
本文将深入探讨基准测试过程,但请记住以下关键点:RedisTimeSeries 速度快……非常快! 这使得 RedisTimeSeries 成为在 Redis 中处理时序数据的最佳选择,远超其他方案:
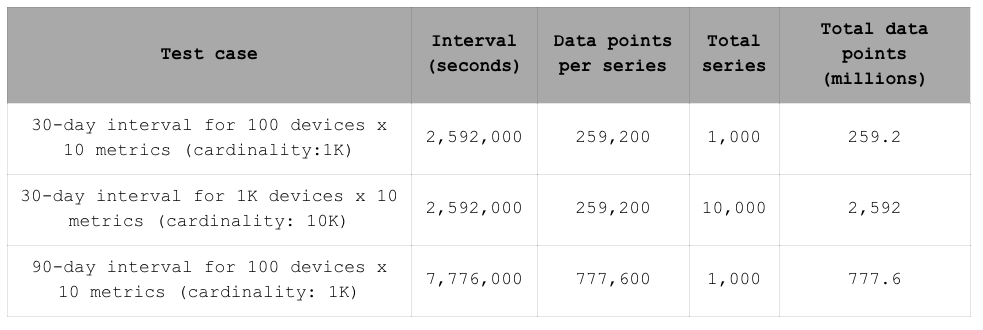
为了比较 RedisTimeSeries 1.2 与 1.0.3 版本的性能,我们选择了三个数据集:前两个数据集每个时间序列的样本数量相同,但在基数上有所不同。
注意:时序数据集的最大基数定义为该数据集在任何给定时间点可以包含或引用的不同元素的数量上限。例如,如果一个智慧城市有 100 个物联网 (IoT) 设备,每个设备报告 10 个指标(气温、二氧化碳水平等),分布在 50 个地理位置,则该数据集的最大基数将是 50,000 [100 (deviceId) x 10 (metricId) x 50 (GeoLocationId)]。
我们选择这两个数据集来测试查询/摄取性能与基数的关系。第三个数据集与第一个数据集具有相同的基数,但每个时间序列中的样本数量是第一个数据集的三倍。该数据集用于测试摄取时间与时间序列中样本数量之间的关系。
性能基准测试在 Amazon Web Services 实例上运行,通过 Redis 的基准测试基础设施进行配置。基准测试客户端和数据库服务器分别运行在独立的 c5.24xlarge 实例上。这些测试使用的数据库运行在一台安装了 Redis Enterprise 5.4.10-22 版本的机器上。该数据库包含 10 个主分片。
除了这些主要的基准测试/性能分析场景外,我们还进行了网络、内存、CPU 和 I/O 的基础基准测试,以了解底层网络和虚拟机特性。我们的基准测试基础设施以代码形式表示,以确保其稳定性和易于重现性。
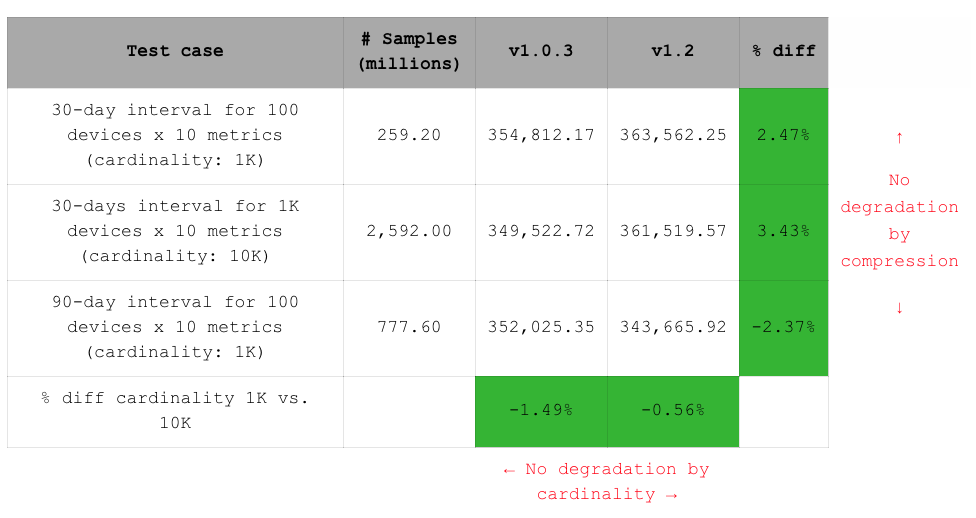
下表比较了 RedisTimeSeries 1.0.3 版本和新版本 1.2 在所有三个数据集上的吞吐量。可以看到,两个版本之间的差异很小。然而,我们引入了压缩,这额外消耗了 5% 的 CPU 周期。由此我们可以得出结论,如果分片未达到 CPU 瓶颈,则压缩不会导致吞吐量下降。
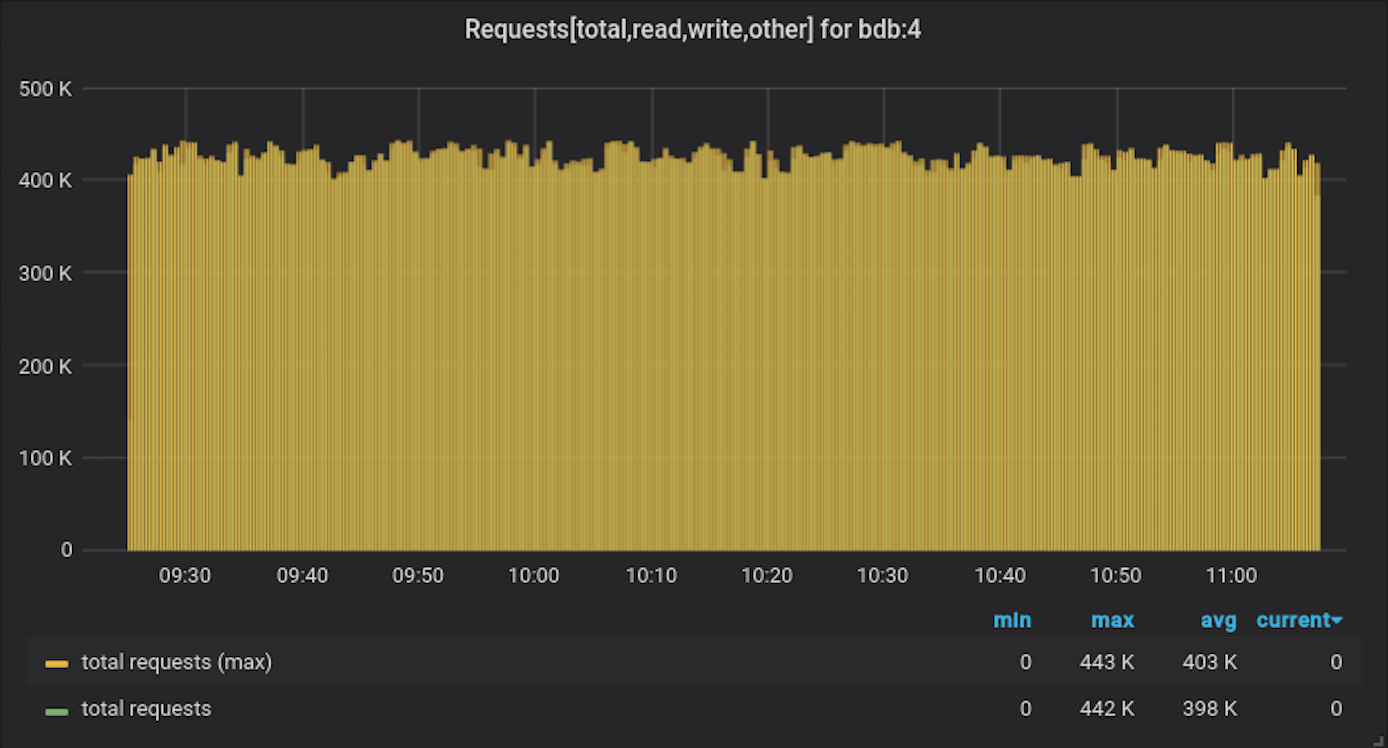
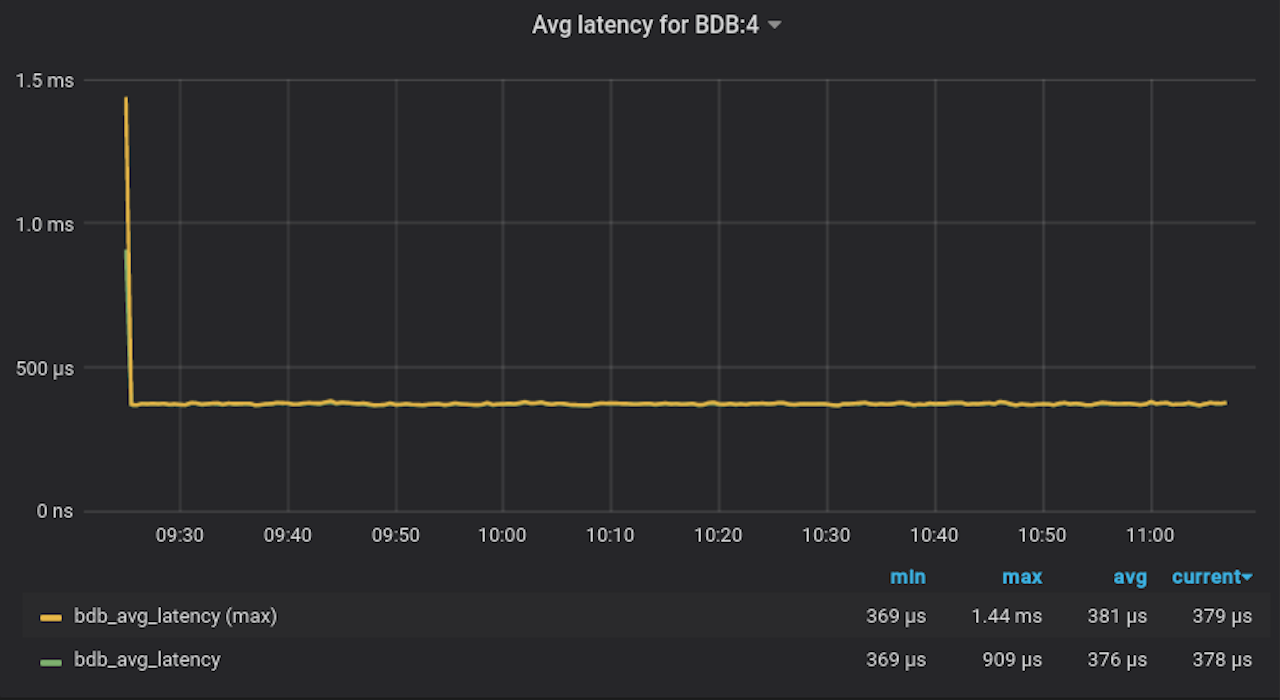
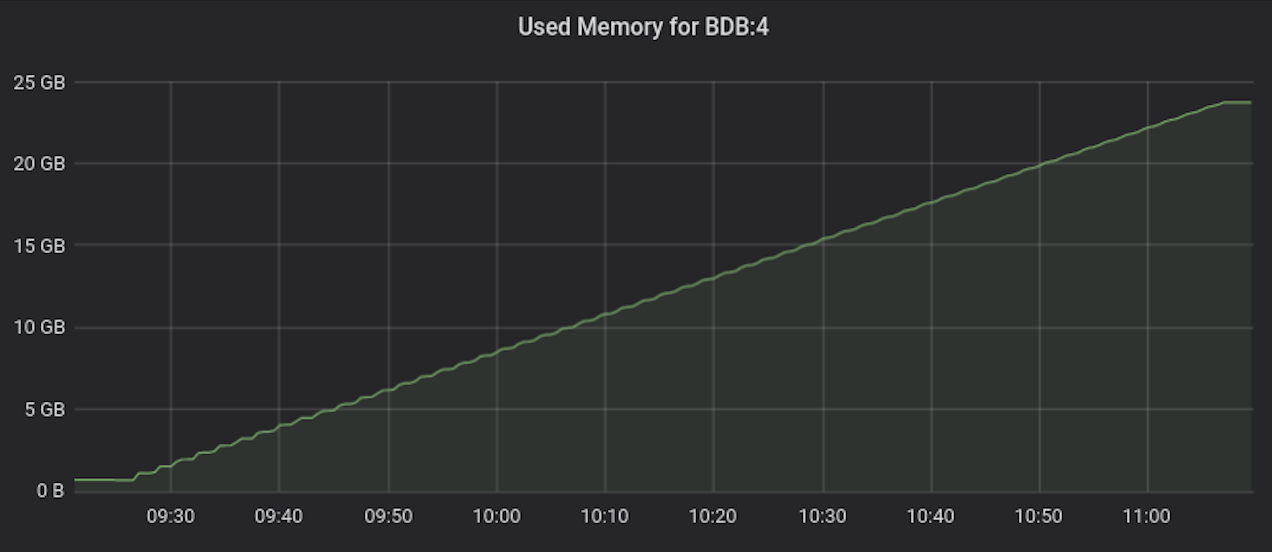
下面三张图跟踪了摄取第三个(也是最大的)数据集期间的吞吐量、延迟和内存消耗。我们在不到两小时的时间内向单个数据库插入了 8 亿个样本。这里重要的是,当一个时间序列中样本数量增加时,延迟和吞吐量不会下降。图表的最后一行比较了前两个数据集的吞吐量。几乎没有区别,这告诉我们当基数增加时,性能不会下降。大多数其他时序数据库在基数增加时性能会下降,这是由于它们使用的底层数据库和索引技术所致。
TSBS 包含一系列不同的读查询。下表显示了比较 RedisTimeSeries 1.0.3 版本与 1.2 版本的多次范围查询的查询速率和查询延迟。它们表明,根据查询复杂性、计算响应所需的访问时间序列数量以及查询时间范围的不同,查询延迟可以降低高达 50%,吞吐量可以提高高达 70%,。总的来说,查询越复杂,性能提升越明显。
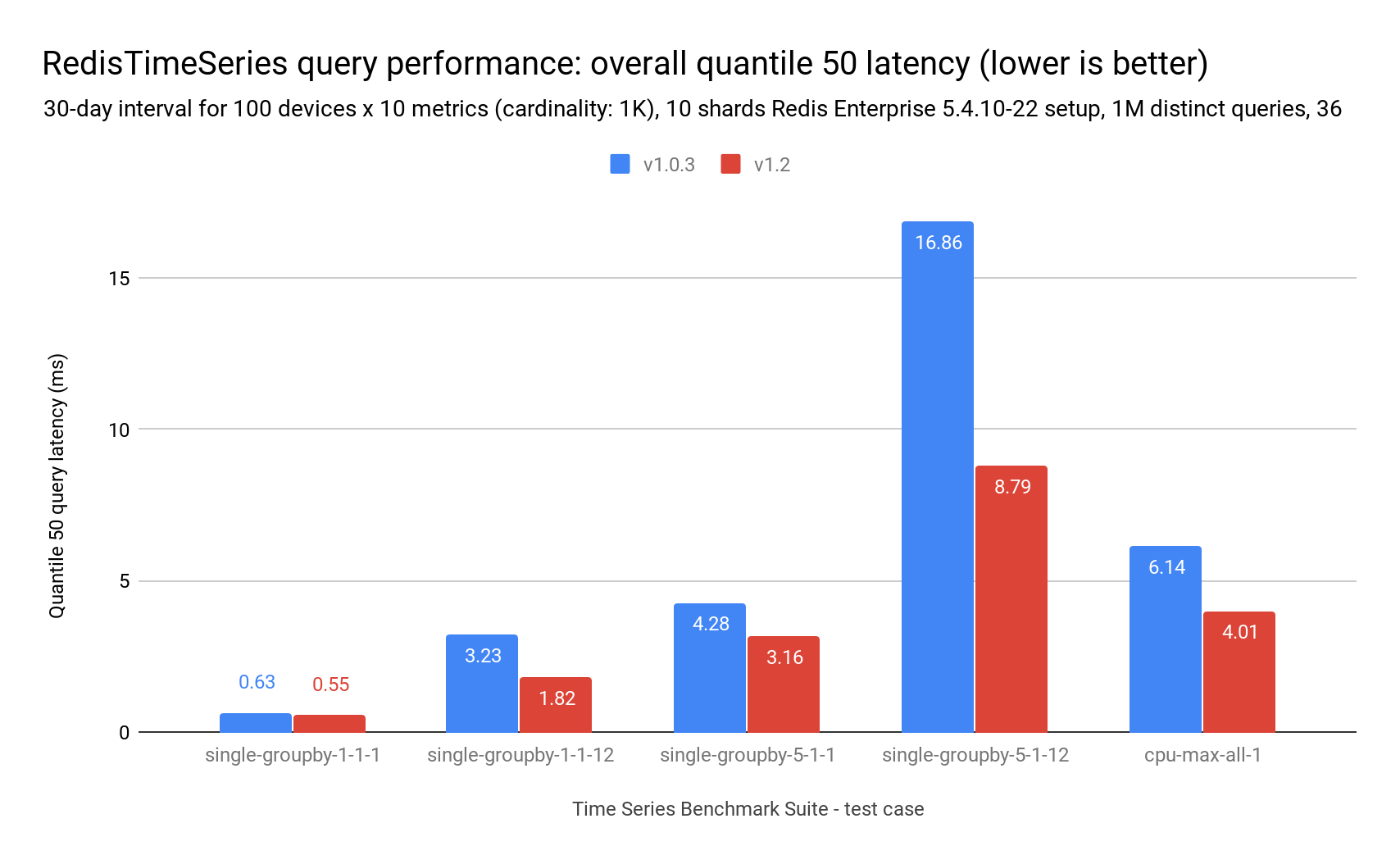
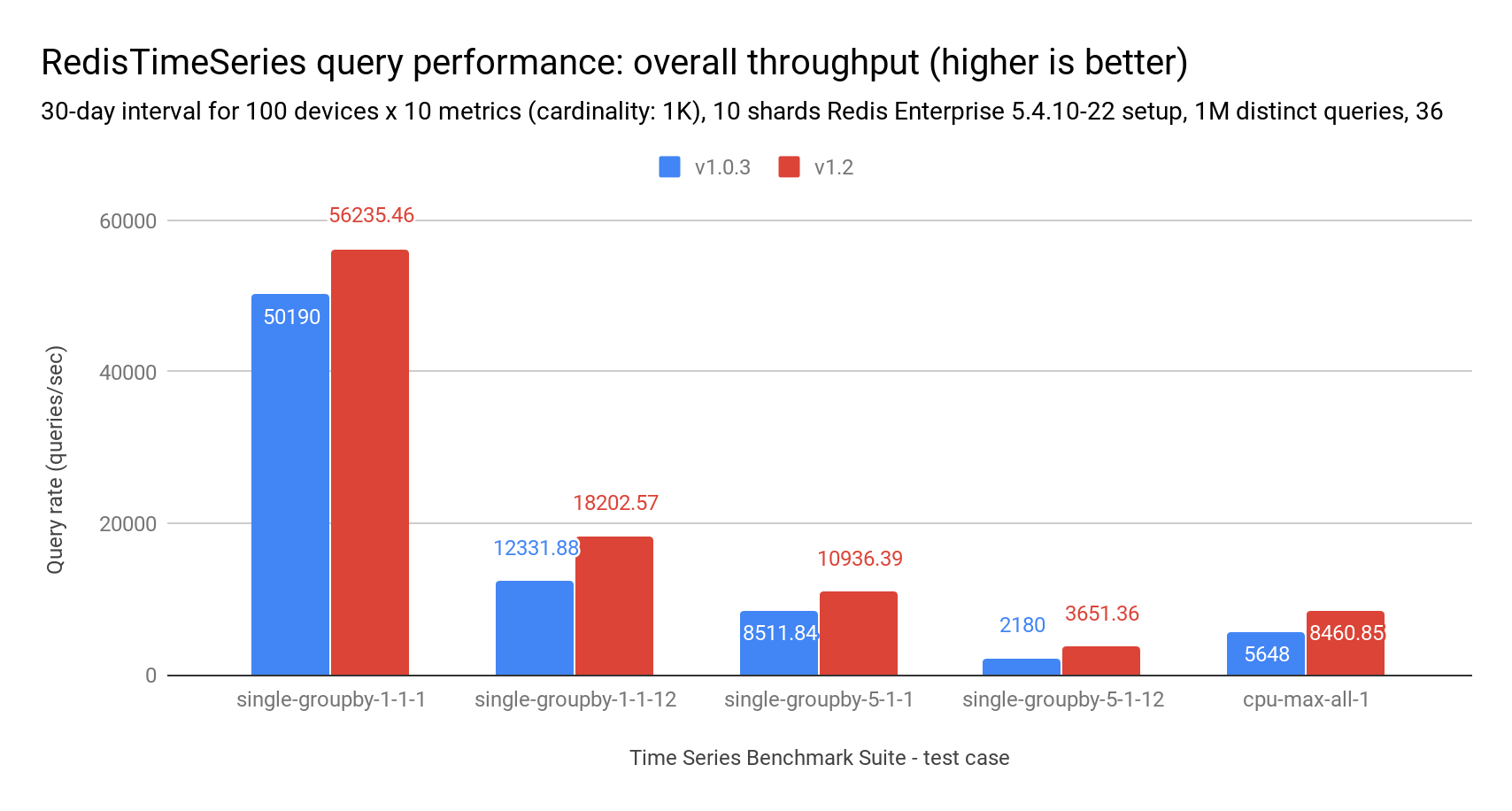
这种表现得益于压缩和 API 的改变。由于更多数据可以存储在更少的内存空间中,因此回答相同的查询所需的内存块访问次数更少。同样,API 默认行为不再返回每个时间序列的标签,这显著降低了每个 TS.MRANGE 命令的负载和整体 CPU 时间。
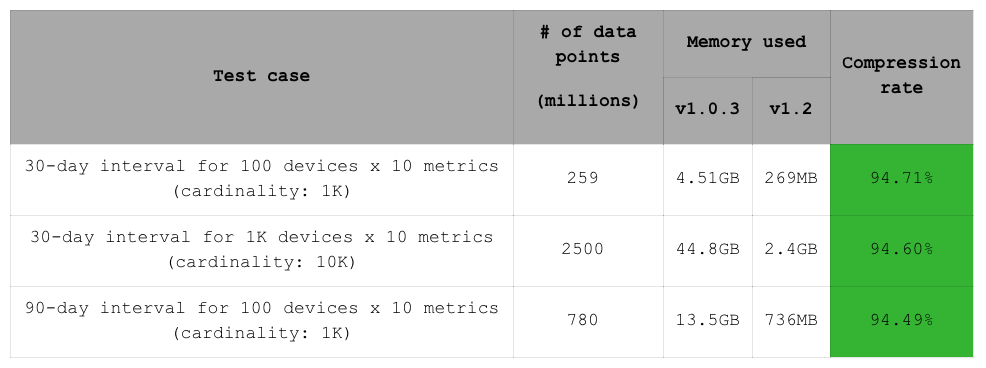
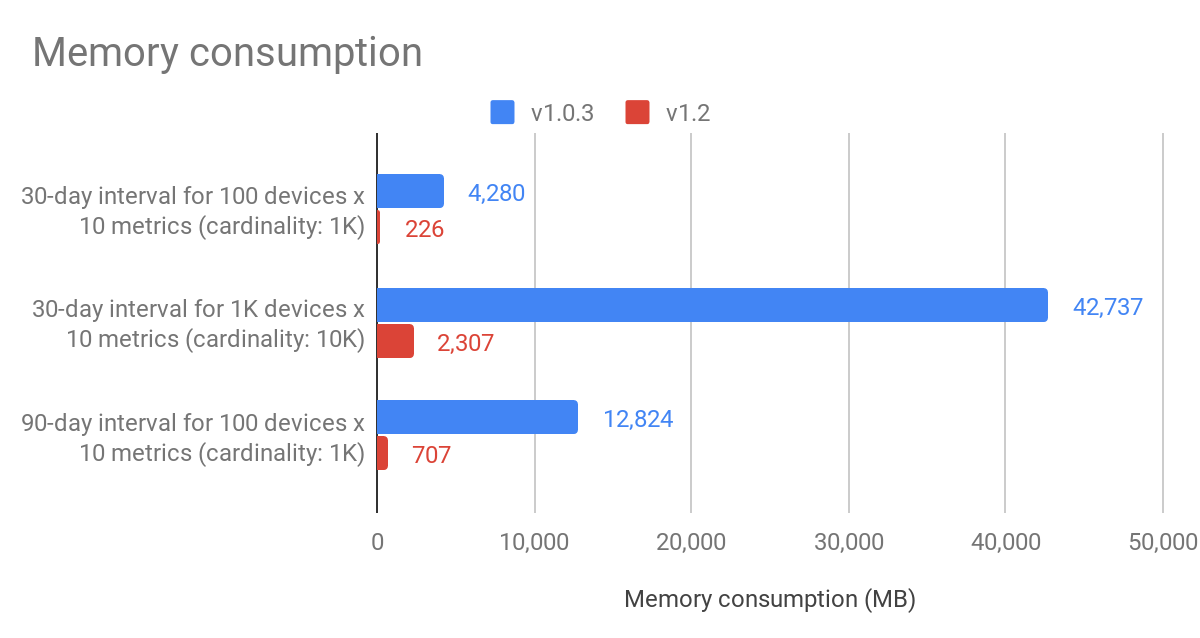
RedisTimeSeries 1.2 中增加了压缩功能,这使得比较这三个数据集的内存利用率变得很有意义。本次基准测试结果显示,所有三个数据集的内存消耗降低了 94%。当然,这是一个实验室设置,时间戳以固定时间间隔生成,这对于双差压缩来说是理想的(关于双差压缩的更多信息,请参阅 RedisTimeSeries 1.2 版本发布!)。正如所提到的,在实际用例中,内存减少 90% 是常见的。
RedisTimeSeries 速度非常快
去年夏天我们推出 RedisTimeSeries 时,我们将其与 Redis 中使用原生数据结构(如有序集合、哈希或流)进行时序数据建模的方案进行了基准测试。在内存消耗方面,除了流之外,它已经优于其他建模技术,流的内存消耗是 RedisTimeSeries 的一半。随着 Gorilla 压缩的引入(更多信息请参阅此文:RedisTimeSeries 1.2 版本发布!),RedisTimeSeries 绝对是 Redis 中持久化时序数据的最佳方式。
除了证明压缩不会导致性能下降外,基准测试还表明,基数或时间序列中的样本数量也不会导致性能下降。所有这些特性的结合在时序数据库领域是独一无二的。再加上大幅提升的读取性能,你绝对会想亲自尝试一下 RedisTimeSeries。
最后,值得注意的是,时序数据库基准测试生态系统非常丰富且由社区驱动——我们很高兴能成为其中的一员。拥有一个共同的基准测试基础对于消除性能瓶颈和强化 RedisTimeSeries 1.2 中的每项解决方案来说,已被证明具有极高的价值。我们已经开始贡献于更好地理解 TSBS 上的延迟和应用程序响应能力,并计划对现有基准测试提出进一步的扩展建议。

