 Redis 8 来了——而且是开源的
Redis 8 来了——而且是开源的
了解更多

当你考虑它时,“生活是一个时间序列”。
所以,即使 RedisTimeSeries 模块(它简化了 Redis 在时间序列用例中的使用,如物联网、应用程序监控和遥测)—已经 自 2019 年 6 月以来全面上市,我们已经看到了大量有趣的用例,这也不足为奇。例如,纽约时报正在其内部 Photon 项目中使用 RedisTimeSeries,正如 Amazon Web Service 的 IoT Greengrass 项目(参见 GitHub repo 此处)。
但我们不是来坐享其成的。相反,我们宣布推出该模块的主要新版本 RedisTimeSeries 1.2 的正式版,该版本 首次亮相,拥有一长串强大的新功能。但鉴于人们的广泛兴趣,RedisTimeSeries 1.2 的主要目标是在不降低性能的前提下提高可用性。由于 Redis 是一个内存数据库,因此在 DRAM 中存储大量时间序列数据可能会变得昂贵。因此,在 1.2 版本中,我们添加了压缩功能,在大多数情况下,它将内存需求降低了高达 90%——理论上,它可以将你的时间序列数据压缩高达 98%! 我们使我们的 API 更加一致和直观,并删除了冗余响应数据,以进一步提高性能。API 更改和压缩共同将 读取性能提高了高达 70%。总而言之,新版本的 RedisTimeSeries 可以在不影响性能的情况下为用户节省大量的基础设施成本。
(查看我们关于 RedisTimeSeries 1.2 基准测试的配套博文,了解更多关于 摄取吞吐量如何独立于数据集中的时间序列数量、压缩以及时间序列中的样本数量的信息。)
但让我们从压缩的工作原理开始,因为它有点酷。
RedisTimeSeries 中的时间序列由块的链接列表组成,每个块都包含固定数量的样本。样本是时间戳和值的 元组,表示特定时间的测量值。时间表示为时间戳,值表示为浮点数 (双精度浮点格式)。这些块本身在 Radix 树中被索引。你可以在 这里阅读更多关于内部的信息。
未压缩时,时间戳和值每个样本消耗 8 字节(总共 16 字节/128 位)。对于时间戳,我们使用双增量压缩,对于值,我们使用 XOR(“异或”)压缩。这两种技术都基于 Facebook Gorilla 论文,并在 我们的源代码中进行了记录,但我们将在下面解释它是如何工作的。
在许多时间序列用例中,样本以固定间隔收集。想象一下,我们每 5 秒从温度传感器收集测量值。以毫秒为单位,两个连续样本之间的增量将为 5,000。然而,由于间隔保持不变,因此两个增量之间的增量—双增量—将为 0。
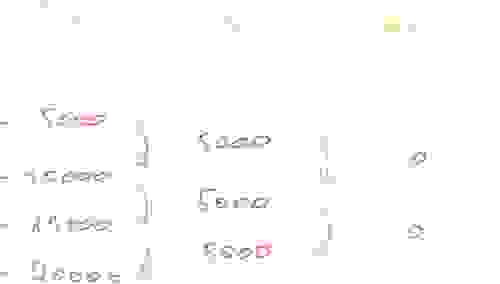
有时数据会在第 6 秒或第 4 秒到达,但通常这是一个例外。与其将此 ΔΔ (双增量) 以 64 位存储,不如根据以下伪代码使用 变长编码:
如果 ΔΔ 为零,则存储单个“0”位
否则如果 ΔΔ 介于 [-63, 64] 之间,则存储“10”,后跟 该值(7 位)
否则如果 ΔΔ 介于 [-512,511] 之间,则存储“110”,后跟 该值(10 位)
否则如果 ΔΔ 介于 [-4096,4095] 之间,则存储“1110”,后跟 该值(13 位)
否则如果 ΔΔ 介于 [-32768,32767] 之间,则存储“11110”,后跟 该值(16 位)
否则 存储“11111”,后跟使用 64 位的 D
值压缩的基础是假设连续值之间的差异通常很小,并且是逐渐发生的,而不是突然发生的。此外,浮点数本质上是浪费的,并且包含许多可以消除的重复零。因此,当两个连续值进行 XOR 时,结果中只会存在几个有意义的位。为简单起见,下面的示例使用单精度双精度数——RedisTimeSeries 使用双精度双精度数

你可以看到,前两个相等的数字之间的 XOR 操作显然是 0。但通常在有意义的 XOR 值周围也有许多前导和尾随 0。值的 XOR 差异的变长编码删除了前导和尾随零。
还有一个控制位可以进一步减少样本消耗的位数。如果 有意义的位块落在先前值的有意义的位块内,即,至少有与先前值一样多的前导零和尾随零,则可以使用先前样本的前导零和尾随零的数量:
如果 XOR 为零(相同值)
存储单个“0”位
否则
计算 XOR 中前导零和尾随零的数量,
存储位“1”,后跟
如果 有意义的位块落在先前有意义的位块内,
存储控制位“0”
否则存储控制位“1”,
在接下来的 5 位中存储前导零的数量的长度,
在接下来的 6 位中存储有意义的 XOR 值的长度。
最后 存储 XOR 值中有意义的位。
那么这种技术可以为你带来多少内存减少?毫不奇怪,实际的减少取决于你的用例,但我们在基准测试数据集中注意到减少了 94%。根据 Facebook 的 Gorilla 论文的第 6 页,每个样本平均消耗 1.37 字节,而之前是 16 字节。这导致了对于最常见的用例,内存减少了 90%。
当双增量为 0 并且 XOR 也为 0 时,达到理论极限。在这种情况下,每个样本使用 2 位而不是 128 位,从而使内存减少 98.4%!在最坏的情况下,一个样本消耗 145 位:时间戳 69 位,值 76 位。(要发生这种极端情况,双增量必须超过 MAX_32,并且浮点值将非常复杂且不同。因为我们不想排除甚至极端的用例,所以你仍然可以在创建时间序列时使用 `UNCOMPRESSED` 选项。)
时间序列用例主要是仅追加的,这允许进行优化,例如上面描述的压缩。但使用这种压缩方法,插入一个时间戳早于最后一个样本的样本不仅会引入更复杂的逻辑并消耗更多的 CPU 周期,还会需要更复杂的内存管理。
这就是为什么在 RedisTimeSeries 1.2 中,我们使 API 更加严格,不再允许客户端重写时间序列的最后一个样本。这听起来可能有些限制,但大多数更改都是直观的,并且实际上增强了开发人员的体验。
因此,对降采样时间序列的聚合样本的自动计算现在发生在源时间序列上。只有当聚合时间窗口过去后,代表聚合的样本才会被写入降采样时间序列。这意味着写入降采样时间序列的频率降低,从而进一步提高摄取性能。
通过降采样,您可以通过聚合更早之前的样本来减少内存消耗。但您也可以为固定大小的时间窗口建模计数器,例如每小时的网站页面浏览量。您可以使用 RedisTimeSeries 轻松构建这些计数器。在源时间序列中,您使用 TS.ADD 添加一个样本,其值为您希望计数器增加的值,并使用一个sum聚合,并指定固定窗口大小的降采样规则:
redis:6379> TS.CREATE ts RETENTION 20000
OK
redis:6379> TS.CREATE counter
OK
redis:6379> TS.CREATERULE ts counter AGGREGATION sum 5000
OK
redis:6379> TS.ADD ts * 5
(integer) 1580394077750
redis:6379> TS.ADD ts * 2
(integer) 1580394079257
redis:6379> TS.ADD ts * 3
(integer) 1580394085716
redis:6379> TS.RANGE counter - +
1) 1) (integer) 1580394075000
2) "7"
redis:6379> TS.ADD ts * 1
(integer) 1580394095233
redis:6379> TS.RANGE counter - +
1) 1) (integer) 1580394075000
2) "7"
2) 1) (integer) 1580394085000
2) "3"
redis:6379> TS.RANGE ts - +
1) 1) (integer) 1580394077750
2) "5"
2) 1) (integer) 1580394079257
2) "2"
3) 1) (integer) 1580394085716
2) "3"
4) 1) (integer) 1580394095233
2) "1"
redis:6379>
在这两种情况下,降采样序列都将具有您正在寻找的确切计数器。
添加 Gorilla 压缩和 API 增强功能显着降低了内存消耗。(有关其工作原理的更多信息,请参阅关于 RedisTimeSeries 1.2 基准测试的配套博客文章。)
但我们还没有完成。展望未来,我们计划使用RediSearch中的新底层 API 替换 RedisTimeSeries 使用排序集合的专有二级索引。这将使用户能够使用丰富且经过验证的查询语言对链接到时间序列的标签执行全文搜索查询。我们还在努力完成我们的 API,通过引入 TS.REVRANGE 和 TS.MREVRANGE 命令来与其他 Redis 数据结构保持一致。
大多数 Redis 模块都专注于非常出色且非常快速地解决一个特定问题——将它们结合起来可以实现大量有趣的新用例。我们目前正在探索将 RedisTimeSeries 和RedisAI结合起来以进行实时异常检测和无监督学习。最后,我们正在努力为RedisGears公开一个底层 API,这将允许您以最高性能的方式进行跨时间序列聚合。

