 Redis 8 已发布,并且它是开源的
Redis 8 已发布,并且它是开源的

视频

2022 年 RedisDays 伦敦回顾
了解更多

在 21 世纪,数据已成为企业最宝贵的商品。从始至终,每一个大型公司的成功都取决于其收集、处理、管理和利用数据的能力。
为了更好地利用您的数据,请阅读我们的电子书,了解最常见的数据迁移错误
数据管道已成为将数据从一个地方传输到另一个地方,并使其随时可用于分析的关键。数据管道消除了流程中的大多数手动步骤,为您提供了更快、更可靠的洞察,将推动您更接近实现目标。
下面我们将深入探讨数据管道的一切,以及如何充分利用数据来获得竞争优势。
数据管道是采取的一系列操作,将原始数据从不同位置传输到可以存储和分析的地方。当数据以最纯粹的形式收集时,可能未针对分析进行优化。因此,数据管道的一个关键作用是以适合报告和用于生成关键业务洞察的方式转换这些原始数据。
数据管道流程可以分为三个不同的阶段。
来源本质上是数据收集的位置。这些位置包括关系型数据库管理系统,例如
在许多情况下,数据被摄取从不同来源,然后根据业务需求进行处理和转换。
最后一个阶段是将数据传输到其预期的存储位置,通常是数据湖或数据仓库,以便进行分析。
基于批处理的数据管道是最常见的类型之一,可以手动或定期部署。顾名思义,它们按批次处理数据。在这种架构下,可能存在一个应用生成广泛的数据点,需要将其传输到数据仓库和用于分析的位置。
基于批处理的数据管道在一个周期性流程下运行,每个周期在所有数据处理完毕后完成。完成一次运行所需的时间取决于所消耗数据源的大小,范围从几分钟到几个小时不等。
激活时,基于批处理的数据管道会给数据源带来更高的工作负载。因此,企业倾向于在用户活动较低时部署它们,以避免影响其他工作负载。
它们通常用于对时间敏感度要求不高的情况,例如
下面是一个基于批处理的数据管道的示例

在我们这个每天产生海量数据的世界里,企业已将流式数据管道视为一种更优的数据收集、处理和存储方式。这是因为流式数据管道持续运行,其架构使其能够大规模、实时地执行数百万个事件。
它们用于需要数据新鲜度且组织需要对市场变化或用户活动立即做出反应的场景。例如,如果我们的目标是监控网站或应用上的消费者行为,数据将基于数千个事件,每个事件有数千个用户。这很容易每小时产生数百万条新记录。
如果组织必须对实时看到的变化(例如应用或网站宕机)立即做出响应,那么使用流式数据管道将是唯一可行的选择。
流式数据管道的典型用例包括
下面是一个流式数据管道的示例
ETL 代表“提取、转换、加载”,是一种数据集成过程,使数据可供企业利用。ETL 管道允许您从一个或多个来源提取数据,对其进行转换,然后将其推送到数据库或仓库中。
它们本质上由三个相互依赖的数据集成过程组成,负责将数据从一个数据库传输到另一个数据库。数据管道和 ETL 管道之间存在三个根本区别。
ETL 管道过程的最后一个阶段是将数据传输到数据库或仓库中。这与数据管道不同——数据管道并不总是以加载过程结束。使用数据管道,加载可以通过激活其他系统中的 webhook 来启动新过程。
尽管数据管道在不同系统之间传输数据,但它们并不总是涉及数据的转换,这与 ETL 管道不同。
ETL 管道倾向于按批次运行,数据定期按块移动。相反,数据管道通常作为涉及流计算的实时过程运行。
需要强调的是,数据管道本身是将数据从源系统传输到目标系统的过程,而数据管道架构是一个全面的系统,负责提取、管理并将数据连接到其他不同的组件。整个过程通常包括四个步骤
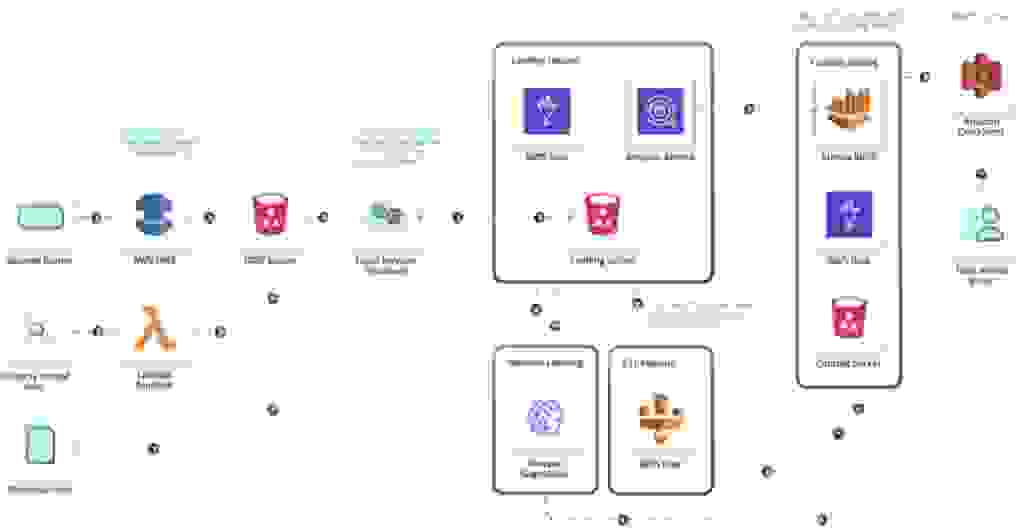
数据管道可以分解为可重复的步骤,为自动化铺平道路。自动化每个步骤可最大限度地减少阶段之间人为瓶颈的可能性,从而让您以更快的速度处理数据。
自动化数据管道可以在短时间内传输和转换大量数据。更重要的是,它们还可以同时处理多个并行数据流。作为自动化过程的一部分,任何冗余数据都将被提取,以确保您的应用和分析工具以最佳状态运行。
您收集的数据很可能来自各种不同的来源,这些来源将包含不同的特征和格式。数据管道将允许您处理不同形式的数据,无论其独特特征如何。
数据管道将以针对分析优化的方式聚合和组织您的数据,为您提供快速、即时访问可靠洞察的能力。
数据管道使您能够通过利用等其他工具从数据中提取额外价值,例如机器学习。通过利用这些工具,您将能够对您的洞察进行更深入的分析,从而发现隐藏的机会、潜在的陷阱以及改进运营流程的方法。
Astera 易于使用且有效,可以从任何云端或本地来源提取数据。使用此工具,可以根据您的业务需求对数据进行清洗、转换并发送到目标系统。更重要的是,您可以在一个平台上完成这一切。
Hevo Data 是一个无代码管道,允许您将数据从不同来源实时加载到您的数据湖。该工具高效省时,旨在尽可能轻松地跨不同平台跟踪和分析数据。
该工具帮助您自动化报告流程。只需连接 100 多个不同的数据源,并以不同的格式进行检查即可。
Integrate.io无需代码,通过 ETL 过程(提取、转换、加载)将数据从源 A 传输到源 B。这个用户友好的工具通过几乎(或根本)不需要代码的连接器连接不同的数据源和目的地,从而允许您将关键业务信息从不同来源转移用于分析。
数据源连接能力
您可以使用预构建的连接器从 100 多个不同来源提取数据。这包括集成 SaaS 软件、云存储、SDK 和流服务。
无缝部署
通过其简单且交互式的用户界面,只需几分钟即可设置管道。部署非常容易,您将进行分析以优化数据集成调用,而不会影响数据质量。
随数据增长而扩展
随着数据量和速度的增加,您可以进行水平扩展。Hevo Data 可以以低延迟每分钟处理数百万条记录。
Redis是一个实时内存数据平台,提供低延迟、高吞吐量、高度可扩展且低成本的数据摄取、数据处理、数据和特征服务。高性能数据管道的意义在于尽可能快地将数据提供给客户使用的服务,甚至直接提供给客户。关系型数据库(RDBMS)甚至某些 NoSQL 数据库都无法提供像 Redis 这样的内存解决方案的速度和性能,因此将 Redis 包含在您的管道中以支持实时用例至关重要。
内存速度
Redis Enterprise 每秒可以处理超过 2 亿次读/写操作,并达到亚毫秒级延迟。
成本效益高的存储
Redis on Flash通过用 SSD 扩展 DRAM,实现了成本效益高的存储,并允许摄取非常大的多 TB 数据集,同时即使在以每秒超过 100 万个项目的速度摄取数据时,延迟也能保持在亚毫秒级水平。
数据类型灵活性
Redis 是最适合数据管道的数据库之一,因为它支持所有原生数据类型,例如:

